Python機器學習:預測股市漲跌 隨機森林Random Forest
前言
今天將會分享如何使用python的sklearn機器學習中的隨機森林random forest,預測台灣加權指數的漲與跌的機率,而機器學習與隨機森林背後的演算法與邏輯不在此文章詳述。

將學習到
- sklearn中的隨機森林、分類結果報告、roc-auc的準確率
- yfinance取得台灣加權指數資料
- matplotlib.pyplot繪製roc-auc曲線
環境設定
win10 Anaconda的jupyter(6.0.3)
如果數據很龐大,建議可以使用google提供的colab。
使用套件
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import classification_report
from sklearn import metrics
import yfinance as yf
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd如未有上述套件請先使用pip安裝,像是yfinance就會是pip yfinane,但每個套件的安裝方法不盡相同,可在安裝前搜尋。
開始工作
步驟1:取得資料
import yfinance as yf
df = yf.download('^TWII','2010-04-27','2021-04-27,interval = '1d')- 當中
yf.download(查詢標的,開始時間,結束時間,k線時間)。 - 查詢標的:
’^TWII’是台灣加權指數,如果要查台積電則是’2330.tw’、蘋果’AAPL’、特斯拉’TSLA’。 - 開始時間
strat與結束時間end:皆以字串表示,像是’2021–04–27’。 - k線時間
interval:1m,2m,5m,15m,30m,60m,90m,1h,1d,5d,1wk,1mo,3mo,可以自由取得日K、周K、月K。 - 取得期間
period:如果不想要指定日期的期間還可以用期間period的方式取得,可以設為1d,5d,1mo,3mo,6mo,1y,2y,5y,10y,ytd,max,取得近5日、近6個月、近5年。 - 關於
yfinance的更多資訊請詳閱yfinance
步驟2:整理資料
df['Open-Close'] = (df.Open — df.Close)/df.Open#當日開盤價與收盤價漲幅
df['High-Low'] = (df.High — df.Low)/df.Low#當日最高價與最低價漲幅
df['percent_change'] = df['Close'].pct_change()#每日收盤價幅度
df['std_5'] = df['percent_change'].rolling(5).std()#5日標準差
df['ret_5'] = df['percent_change'].rolling(5).mean()#5日平均
df.dropna(inplace=True)#清除是na的資料此步驟並非為必要,只是運用股價相關的資料做簡單處裡,如果想要運算更加複雜與進階的資料,像是kd值、MACD、布林通道、可以運用python的ta-lib,可以參考用Python超簡單計算:158種常見技術指標,順便推薦FinLab,當中也介紹相當多有關金融科技的技術與知識。
步驟3:設定label與變數,以及將資料分為訓練集與測試集
# X is the input variable
X = df[[‘Open-Close’, ‘High-Low’, ‘std_5’, ‘ret_5’]]# Y is the target or output variable
y = np.where(df[‘percent_change’].shift(-1) > 0, 1, 0)
- X:變數是指希望哪些參數可能會影響結果
- Y:label是指最後的結果,而上述程式碼是當每日的當跌超過0,也就是有漲,則標註為1,反之則為0。
- 關於X與Y就像是生活中的生理女性與生理男性,當嬰兒出生時可以簡單用外顯特徵-生殖器辨認生理性別,當中外顯特徵就是X,而是男性或是女性就是因X而影響結果Y。
#分割訓練集跟測試集
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.25, random_state = 0)在機器學習中常用訓練集與測試集建立機器學習,當中的test_size=0.25就是將整筆資料中的25%設為測試集而75%設為訓練集。更多資訊請詳閱sklearn.model_selection.train_test_split。
步驟4:使用隨機森林Random forest建模與取得報告
from sklearn.ensemble import RandomForestClassifier
clf = RandomForestClassifier(n_estimators=1000, random_state=10, n_jobs=-1, min_samples_leaf = 5)#隨機森林參數設定# Create the model on train dataset
model = clf.fit(X_train, y_train)#開始訓練
y_pre = clf.predict(X_test)#預測結果
from sklearn.metrics import classification_report
report = classification_report(y_test, y_pre)#訓練後報告
RandomForestClassifier中有許多可以設定的參數而關於更多的設定可以參考sklearn.ensemble.RandomForestClassifier。
n_estimators=1000為The number of trees in the forest.意味著要種幾棵樹,關於要種幾棵樹沒有一定的答案,可以依照自己的訓練後調整。
random_state=10為Controls both the randomness of the bootstrapping of the samples used when building trees.
n_jobs=-1為The number of jobs to run in parallel. fit, predict, decision_path and apply are all parallelized over the trees. None means 1 unless in a joblib.parallel_backend context. -1 means using all processors.在跑演算法的同時想要用哪種方法,而-1則為全部的方法。
min_samples_leaf = 5為The minimum number of samples required to be at a leaf node. A split point at any depth will only be considered if it leaves at least min_samples_leaf training samples in each of the left and right branches. This may have the effect of smoothing the model, especially in regression.當森林過大時會導致Overfitting過度配置,所以需要修剪過多的樹枝或樹葉。
關於Overfitting是機器學習常遇見的問題,想知道更多Overfitting的問題可參考[機器學習 ML NOTE]Overfitting 過度學習。
classification_report是檢視經機器學習後的準確率報告,關於其中可參考sklearn.metrics.classification_report或是机器学习classification_report方法及precision精确率和recall召回率 说明。
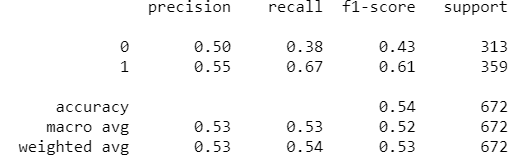
步驟5:繪製roc-auc曲線
#計算roc-auc
from sklearn import metrics
fpr, tpr, thresholds = metrics.roc_curve(y_test, y_pre)
auc = metrics.auc(fpr, tpr)#繪製roc-auc
import matplotlib.pyplot as plt
plt.plot(fpr,tpr,label="random forest, auc="+str(auc),color='blue')
plt.title("ROC")
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.legend(loc=4)
plt.show()
roc-auc是一種判斷機器學習後分類的結果是良好,ROC曲線下方覆蓋的面積(AUC)越大,表示效能越好。可參考淺談機器學習的效能衡量指標 (2) — ROC/AUC 曲線。

完整程式碼
小結
利用python的sklearn機器學習真的很方便也很易懂,本篇雖然用了機器學習做預測漲跌,但在金融商品的實務中不僅是需要漲跌預測,像是資金管理、市場訊息或是Elon Musk在twitter的發言都是有影響力的,機器學習本人認為是一項參考工具,對於實際市場的變動絕不是單一面向的,但到頭來還是需要有一套自己的交易策略以及心法。
如果你對於以上的內容有建議歡迎提出,一起討論絕對是成長的捷徑!!
